How to deploy multiple ASP.Net Core Microservices from a monorepository
Currently I’m working on a project that has several small services, that communicate through posting events through Azure Event Hubs.
One service posts data to an event hub, and another service reads it, and each service lives in its own repository with no shared code.
Now this project is still at its very early stages - which means nobody knows what they’re doing yet. As we learn more about the problem domain, the structure of the events change frequently. Changing these event models take a lot of time. Coordinating between multiple services is always expensive, but especially when they’re in multiple repositories. Every time we want to update the event model, we have to change each service, making sure not to forget any. We also have to make sure we don’t have any typos in one of the services, or we’ll end up with one service sending events the others can’t read.
This is way too much overhead, coordination-wise, this early in a project.
We went looking for a solution that fulfills the following criteria:
- We want to be able to share code between services, and make service-wide refactorings
- We still want to be able to deploy the services separately
- We want the solution to be as light-weight as possible, so we don’t have to spend time setting up tooling
Enter the monorepository
We ended up with a Monorepository to solve our problems. Inside the monorepository, we have a Shared projects, where code that’s relevant for multiple services lives. Each service has a project reference to the Shared project.
In Shared projects, we have utility methods, extension methods, and all models that are used in more than one service. This is also where all of our third party NuGet dependencies are referenced. Other services that have a reference to the Shared project, will then pick up the NuGet dependencies through that. This ensures we’re always running the same version of our dependencies on each project, so we don’t end up in situations where we upgrade the dependency one place, but not in others.
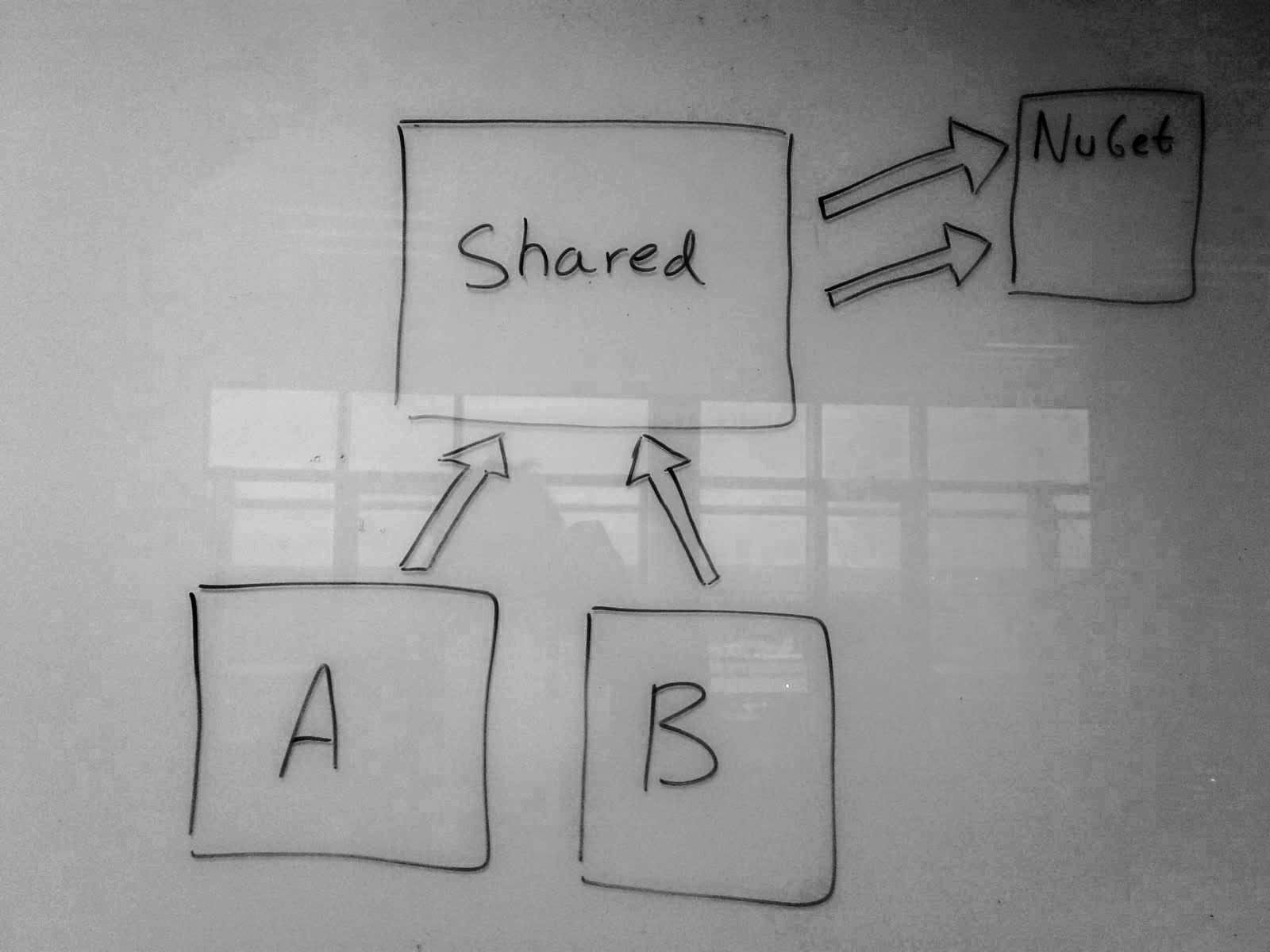
Project A and B, both reference the Shared project. They are able to access all the code in the Shared project, and all of the NuGet dependencies of the Shared project as well
We’re still able to deploy the services individually. When the master branch is updated, we build a Docker image for each project and deploy them individually to different services.
What about tests?
We have a Test project for each service. These all reference the project they’re testing, and a Shared.Tests project. Shared.Tests contains code for testing the Shared library, and all third-party testing dependencies needed. The only third-party dependency the other test projects have, is Microsoft.NET.Test.Sdk - because otherwise the dotnet test runner won’t pick up that it’s a project that contains tests.
What about publishing the shared code as a library?
It’s a good option, which comes with all sorts of nifty advantages, such as being able to version your shared dependencies, if you only have time to update one service.
Unfortunately there’s also several drawbacks, especially in a project this small. We’d have to invest in setting up the tooling to maintain and publish the package. But more importantly, we’d be unable quickly do Solution-wide refactorings. Keeping it all in one repository means that if I need to rename a class, I can do so quickly - everywhere. As project complexity and team size grows, this is probably something you’ll want to do less and less, but in the start, it’s extremely valuable.
What about versioning the models?
Versioning your API is important and when deploying multiple services, you should consider their interaction between them as an API contract, that you can’t just go around changing as you feel like it.
After all, you might want to deploy a new version of only one of your services. This means that if you’re going to change an API in that service you’ll have to version it, or at least make sure it’s backwards compatible.
Versioning solves the problem that you might have different versions of services talking to each other. We’re not in production yet so we’re not going to have that problem - and if we do, we don’t care. Data versioning matters when you’re going into production, but maintaining different versions of your APIs before that is needless overhead.
Did you enjoy this post? Please share it!
I'm Gustav (Mastodon), I'm currently a Staff Engineer at Climatiq, where we provide an API for all sorts of carbon emission accounting. I currently work mostly with Rust, but I've worked extensively with C#, Node, React, React Native, Typescript and Django.
All content on this website is written by a human. See the AI policy.
See an error? Submit a Pull Request and help fix it!
Back to the front page?