Carbon Aware Computing: A Quick Overview
The overarching principle of carbon-aware computing is that you should do more when the electricity is greener, and less when it is not. This is most often accomplished in three ways:
- Location shifting: You switch your servers around to where the grid is greener.
- Time-shifting: You run your time-insensitive jobs, such as machine learning model training or batch processing, when the percentage of renewable electricity in the grid is the highest.
- Demand-shaping: Your software performs less tasks when it can tell that the electricity powering it is dirtier.
While if your infrastructure provider allows you to do these things easily, such as Cloudflare’s Green Compute, you should absolutely take advantage of it.
However, if you don’t have such tools available, you can still achieve a fair chunk of these benefits by going through your infrastructure once without needing to make your software carbon-aware. Let’s take a look.
Location-shifting
While the composition of power grids do vary quite a bit between the worst and the best (Wyoming and Sweden have approximately a 10x difference in CO2 per kWh), the day-to-day or month-to-month differences are much smaller than that.
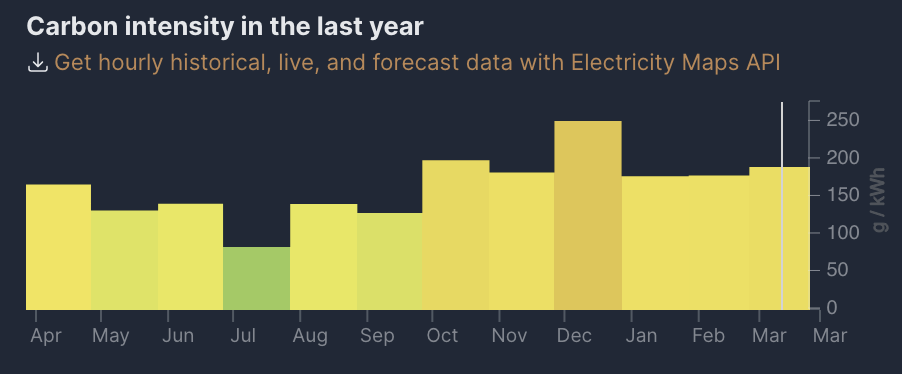 The variance in CO2 per month in Denmark, one of the grids in the world with the highest percentage of renewables. Courtesy of electricitymap.org
The variance in CO2 per month in Denmark, one of the grids in the world with the highest percentage of renewables. Courtesy of electricitymap.org
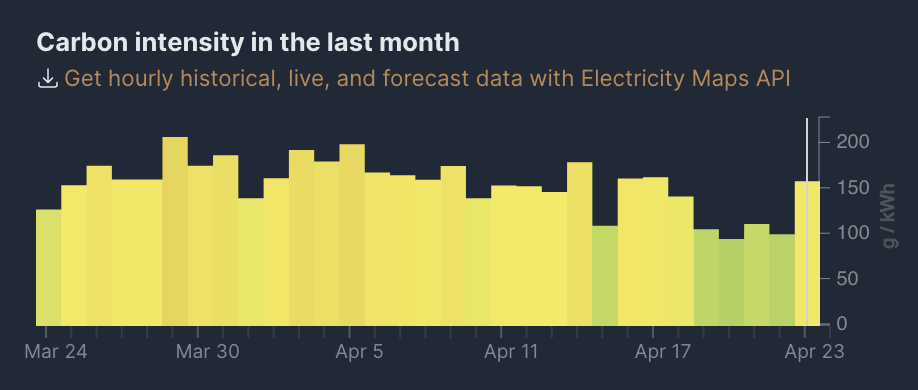 And per day. Also courtesy of electricitymap.org
And per day. Also courtesy of electricitymap.org
That means picking a region with a good renewable-heavy grid gets you a long way without needing to shift around location of your compute jobs. Some cloud providers such as GCP even has tools to help you find the best regions based on the carbon emissions.
Time-shifting
Time-shifting is an interesting concept. It makes sense because the grid production of renewables compared to the general demand for electricity varies from hour to hour. Many grids however have a daily pattern that can take on the following shapes:
- The daytime has more green electricity available, apart from the mornings and afternoons which are (often) when people are doing their cooking. Grids with higher percentage of green energy in the day often contain a high percentage of solar in the mix.
- The nighttime has more green electricity available. This is often the case for grids where wind is a high percentage of energy in the mix.
You can look at electricitymap.org to spot the trends that are relevant to your grid. If you do that, you should be able to get most of the advantage of time-shifting by scheduling your jobs during the time when your grid composition is more favourable, rather than needing to schedule it dynamically.
The Importance of Hardware Utilization
Some of you might be looking at the grid pictures above and (correctly) noticing that there’s a 2x difference between some of my graphs, and wonder what I’m smoking. Reducing your carbon emissions by 50% seems like a huge win.
That wouldn’t be an accurate number though, because actual cloud emissions don’t come from the electricity usage - they come from embodied emissions. Embodied emissions refer to the emissions associated with the production and disposal of servers.
For consumer laptops, embodied emissions make up 75-85% of total emissions, and the general pattern is the same for servers.
 Renting out a VM on Azure. The embodied estimates make up around 65% of the total carbon estimate.
Renting out a VM on Azure. The embodied estimates make up around 65% of the total carbon estimate. Calculations courtesy of climatiq.io
Carbon-aware computing only focuses on the electricity use of your servers, and not the production, lifetime and disposal, where a majority of the emissions come from.
This means that in most cases, looking at optimizing how well we use the physical hardware before we have to replace it, is a better use of our time than trying to switch load around.
Cloud data centers typically replace servers every 4-5 years, making it essential to use them as efficiently as possible. Reducing the number of physical servers and utilizing rented servers at as close 100% capacity can significantly lower the environmental impact. Plus it often leads to better use of resources, resulting in cost savings.
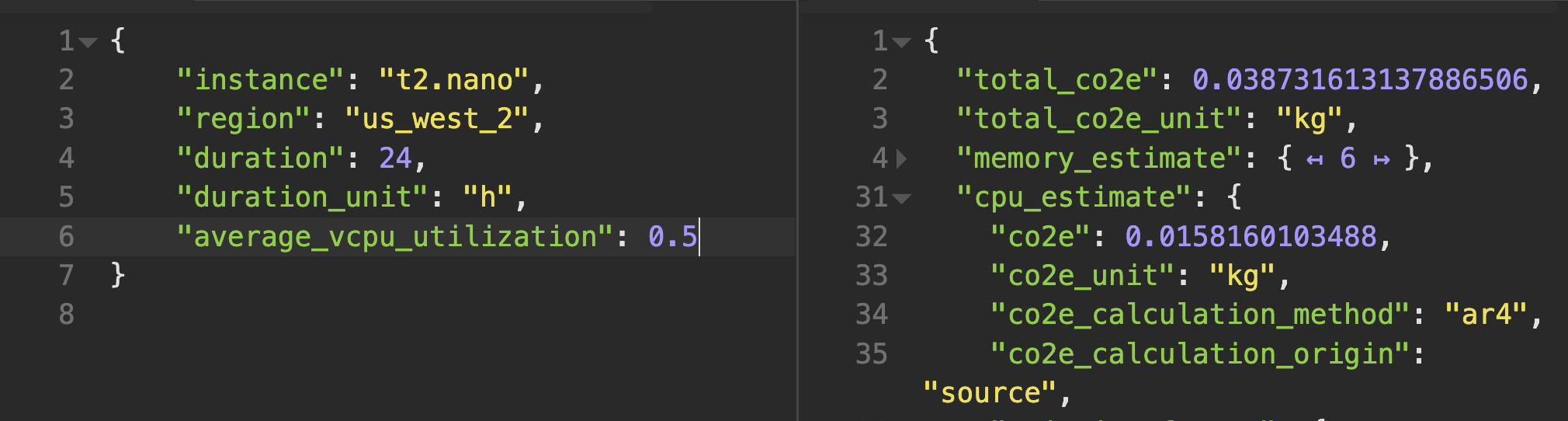
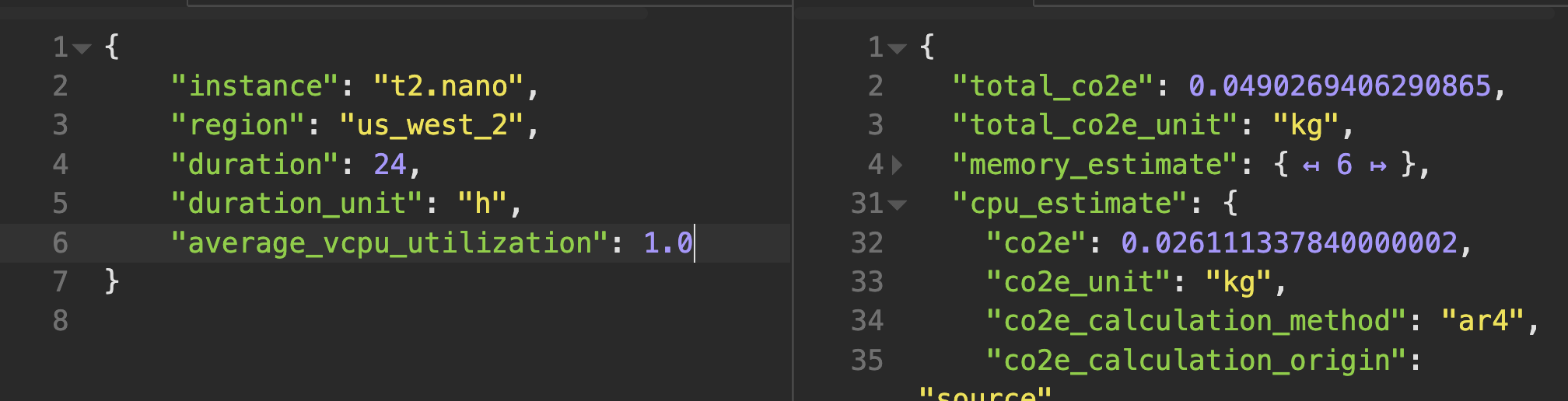 CPU usage in particularly also doesn't scale linearly with electricity as even a CPU at 0% utilization uses power.
This means that the power difference between a CPU running at half versus full utilization is only around 30%.
CPU usage in particularly also doesn't scale linearly with electricity as even a CPU at 0% utilization uses power.
This means that the power difference between a CPU running at half versus full utilization is only around 30%. Calculations courtesy of climatiq.io
So what is the right thing to focus on? If you’re not actively building infrastructure for others to run jobs on, here’s where I think you’ll get the most bang for your buck, in regards to optimizing your computing carbon emissions:
- Don’t spend excessive time on building software that reacts dynamically to the electricity grid, the benefits are marginal.
- Go through your software and choose regions with a more green grid. Often cloud providers give you this information - otherwise you can try using Climatiq’s cloud computing functionality to get a feel for the different regions. If you are not using one of the big three, electricitymap.org is also a good bet to get grid emissions, if you know the location of your datacenter.
- Research if your cloud provider offers ways to switch locations and shift work around to lead to fewer emissions - and use them if they do.
- Consider running time-insensitive jobs on spot instances for both carbon and cost savings.
- If you’re renting virtual machines, try to utilize them as close to 100% as possible, both in regard to CPU usage, but also the amount of memory allocated vs what you actually use. Some things such as serverless or managed platforms might allow your cloud providers to utilize the underlying machines more efficiently than you could yourself.
 17ms latency for an estimate performed via the Climatiq API to a remote server. Is this what the kids call blazing fast?
17ms latency for an estimate performed via the Climatiq API to a remote server. Is this what the kids call blazing fast?
