Achieving Latencies as Low as 30ms for the Climatiq API: How We Do It
Climatiq is an API designed to estimate greenhouse gas emissions for any given activity.
It can be used to batch process large amounts of data, and embedded into other software for informed decision-making, Climatiq aims to provide businesses and developers with a powerful tool to monitor and reduce their carbon footprint.
In this post, we’ll delve into the strategies that help Climatiq achieve ultra-low latencies, consistently under 100ms, and sometimes even as low as 30ms.
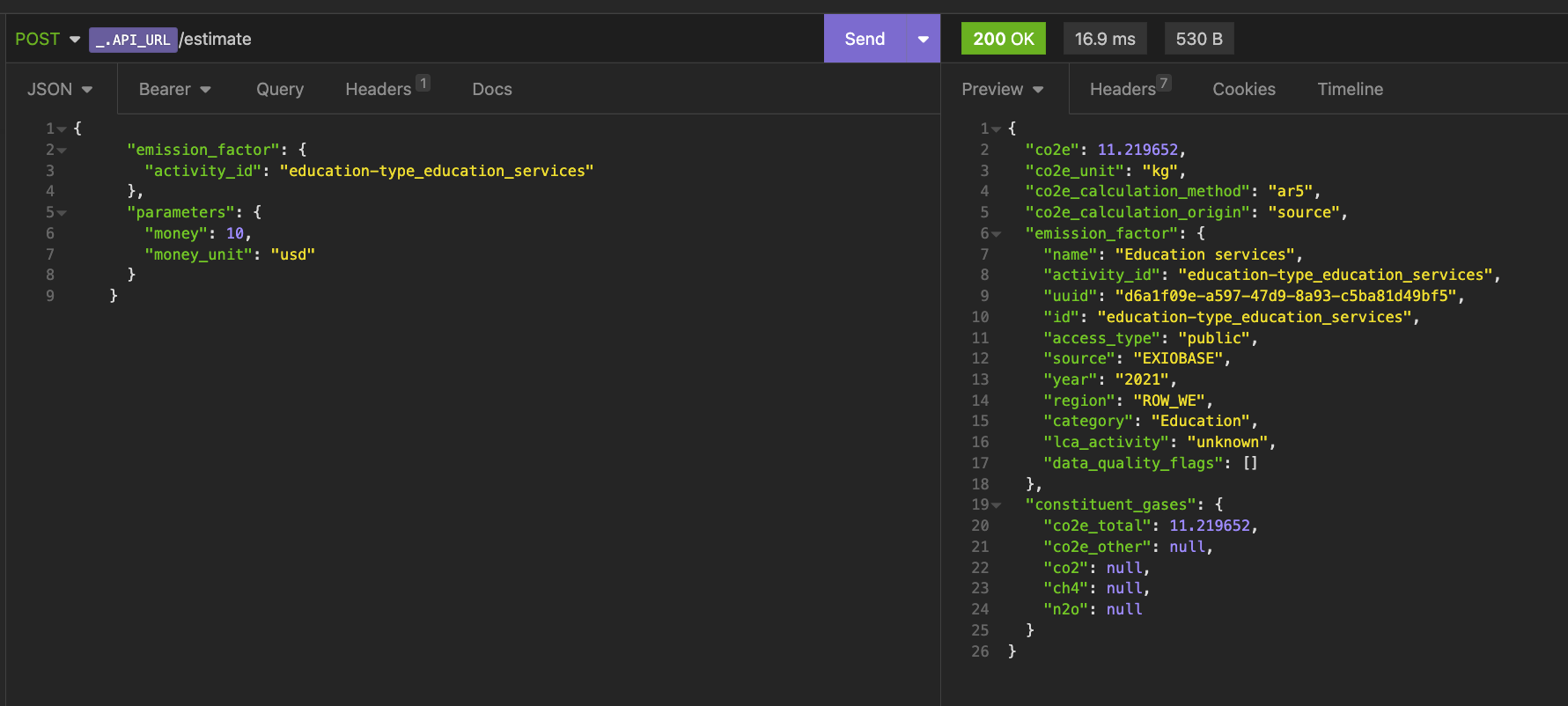 17ms latency for an estimate performed via the Climatiq API to a remote server. Is this what the kids call blazing fast?
17ms latency for an estimate performed via the Climatiq API to a remote server. Is this what the kids call blazing fast?
Disclaimer: Several people have (rightfully) pointed out, that when measuring latency you don’t normally take the network latency into account as it can vary widely depending on your location.
If we only measure latency by the server processing time, our median latency for the endpoint in question is 8.94ms over the last two weeks.
The reason for using the total latency (i.e. network + processing) was to highlight that we serve our API in a geographically distributed manner, so that the network latency will hopefully be low no matter where you are in the world.
The Importance of Performance
But first, let’s disgress a bit and talk quickly about why we care about our API performance - and why you should too.
At this point we might all have heard the old story about how much each millisecond of latency costs Amazon. So more performance equals more money? Sounds like a good argument.
There’s more to it than that though, especially if you want people to embed your API. If you’re faster than a certain threshold, your API feels instantaneous.
This means that people don’t have to worry about loading states, spinners, or their application seeming sluggish.
Not to mention, that as a climate-focused company we should also walk the walk, and every CPU cycle we save, means less electricity used.
Our Strategies for Achieving Low Latency
Embracing Edge Computing
The physical distance between servers and users can significantly impact API response times. To address this challenge, we’ve turned to Fastly’s Compute@Edge platform, running Rust code on a vast edge computing network. This approach allows us to deploy our code across multiple geographically distributed data centers, ensuring that there’s always an API instance nearby to serve requests.
Harnessing the Power of Rust
Rust also plays a crucial role in Climatiq’s performance. Not only for meme-credit, but also for its safety and speed,
Compiling Rust to WebAssembly enables our API to run on the Compute@Edge network, delivering faster performance than many higher-level languages.
While being fast, Rust also provides the expressiveness and high-level features that allow us to quickly iterate and make changes to our codebase.
Minimizing External Dependencies
External dependencies can be a significant source of latency.
Each time you have to reach out to an external service that’s not co-located with yours, you have to wait for them to respond.
To minimize this impact, we ship the majority of our data as a binary blob with the application. Since much of this data seldom changes, this method allows it to be co-located with the code and accessed without any latency overhead.
For necessary external dependencies, we prioritize using geographically distributed solutions like FaunaDB, which replicates data across multiple continents.
Offloading Work Until After the Response
Delaying non-critical tasks until after the client receives their response can improve API responsiveness.
At Climatiq, we use Fastly’s fire-and-forget requests for tasks such as shipping logs and recording metrics. This approach allows us to deliver faster response times without sacrificing data integrity.
Aggressive Caching
In cases where third-party data is required for carbon calculations, we employ aggressive caching strategies when it makes sense.
We leverage the caching capabilities of the Fastly network and the stale-while-revalidate strategy to store third-party responses and serve cached data while new data is fetched in the background.
This approach keeps caching code simple and ensures minimal latency, even when dealing with dynamic data, at the cost of occasionally serving stale data.
Running the right code
We’ve talked a lot about the infrastructure, where we run our code, what it runs on - but very little about what code actually runs.
Most of our code isn’t particularly performance-focused; it doesn’t need to be.
We only have one very hot loop - that’s the loop that when given a user query, finds the data point for them.
This loop has to search through around 50.000 rows, often multiple times in one API call.
We do two note-worthy things to keep this hot loop fast.
-
We benchmark and performance-optimize this. Using the
criterioncrate, we generally benchmark any changes to this loop, to make sure we don’t cause performance regressions.
Actually using benchmarks means that we have numbers that guide what we’re doing. I’ve tried many times to optimize this hot loop, where benchmarks end up showing that we’ve made it slower.
The single largest change was changing from comparing unicode strings, to comparing ASCII strings, which at the time did not seem like an obvious change to make. -
We use the excellent rkyv library, for zero-copy deserialization. This means that we can traverse the binary blob of embedded data without allocating any memory on the heap at all.
This is good because we avoid the performance penalty of allocations, but also because Compute@Edge is a reasonably memory-limited runtime environment, and we’re at the stage now where we’d be overflowing the heap if we had to allocate all our emission factors.
Conclusion
While it’s often said that programmer hours are less expensive than CPU hours, speed still matters to us.
By making our API fast and responsive, we make it easier for developers and businesses to embed Climatiq into their applications, enabling them to calculate and minimize their carbon footprint and make climate-friendly choices in real-time.
If you want to make your application carbon-aware or call bullshit on my speed claims, head on over and try our free trial - no credit card required.

I'm Gustav (Mastodon), I'm currently a Staff Engineer at Climatiq, where we provide an API for all sorts of carbon emission accounting. I currently work mostly with Rust, but I've worked extensively with C#, Node, React, React Native, Typescript and Django.
All content on this website is written by a human. See the AI policy.
See an error? Submit a Pull Request and help fix it!
Back to the front page?