Implementing A Fast Queryable Storage with Apache Avro and Azure Block Blobs
At my employer SCADA MINDS we’re currently working on implementing a data pipeline for one of the larger wind companies in the world. Wind turbines have a lot of sensors, that generate a lot of time-series data. For the amount of turbines we need to support, we need to be able to process upwards of 1GB/sec.
This is a blog post about how, using Azure Block blobs, we’ve made a performant API that can handle that amount of data, and still maintain a respectable latency when queried (<500ms for most cases)
When considering solutions we had a few criteria that needed to fulfill:
-
We need to allow querying on a given sensor for a given time interval
Each sensor on a wind turbine has a uniquesensor id. When you need to query this storage, you always query for a sensor id in a specific time interval. This is the only query type we need to support. -
We need to allow incremental updates of the data
Sometimes sensors go offline or turbines are a little slow to catch up. This means that for a given interval, we’re not sure when we’ll have all the given sensor data. Our solution needs to be able to handle updating the data efficiently. -
Our solution must be cost-efficient
We also need to keep an eye towards cost. While we could fulfill all the other criteria by dumping all of our data inside a managed time-series database, it’s going to end up being very expensive.
We ended up with a solution where we store .avro files in Azure blob storage in a way that effectively allows us to only update and fetch parts of the file. Let’s zoom out a bit and look at the two major components of the solution.
The Structure of an Avro File
An .avro file is a row-based open source binary format developed by Apache, originally for use within the Hadoop. Officially the avro format is defined by the very readable spec, but you can also think of it as a more advanced .csv file.
Like a csv file an avro files also has a header and multiple rows. Unlike csv files, rows in an avro file are compressed and can contain a variable amount of data. Let’s dive a little more into the two parts of an avro file.
Avro File Header
The file header consists of metadata describing the rest of the avro file. It contains the avro schema which is JSON describing the format of the rest of the file. The file header ends with a sync marker, which is a randomly generated block of sixteen bytes. The sync marker is used internally in an Avro file at the end of the header and each data block.
The sync marker is randomly generated when writing a file. It’s unique within the same file but different between files.
Avro Row
After the header the avro file consists of multiple rows. Each row contains encoded data as specified by the header schema. At the end of each block is the sync marker - so we can tell where one row ends and another begins. These are officially called data blocks, but as we have another type of block later, we’ll stick to calling them rows.
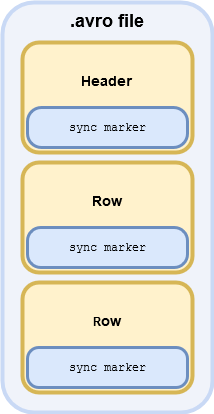 The structure of an avro file
The structure of an avro file
The fact that Avro files are designed this way means that they’re very good at being sliced into pieces and stitched back together again. As long as you know the schema and the sync marker, the rows can both be read and written independently.
We’ll be using that property to construct a storage that efficiently handles both incremental updates, and partial reads of these files.
But first, we need to know a little more about Azure Block Blobs.
The Structure of An Azure Block Blob
The next component we’re using is the Azure Blob Storage, which is a blob-based storage service. However it has a few more tricks up its sleeve than just being able to upload and download arbitrary blobs. It has three different types of blobs, each with their own characteristics. The ones we’ll be using are called block blobs.
A block blob is a blob/file, that consists of several different pieces which are called blocks. Each block consists of some data, and it has a unique block id which we can specify. We use the block id to refer to the block later.
A blob consists of one or more blocks. By re-ordering, replacing or adding blocks to a blob, we’re able to efficiently update and change files with a minimum of work.
 The structure of an Azure Block Blob
The structure of an Azure Block Blob
A word on words: While the “official” terms are blocks and blobs, where one blob consists of multiple blocks, I feel the two terms are a little too close to each other, and I certainly often get confused. From here-on I’ll call the blobs files. It’s less-correct, but hopefully harder to get them mixed up.
Writing files
Writing a file via the block blob interface consists of two parts.
Stage your blocks
The first step is staging the new blocks you want to be part of your blob. You upload some bytes, tag them with a block id, and you’re golden. You can upload any number of blocks, but they’re considered uncommitted, which means they don’t really do anything.
Commit the blocks
The next step is committing the blocks which creates a fully formed file. You commit the blocks by sending a list of block ids to be committed. The file will then consist of these blocks, in the order that the block ids are provided. The block ids can either be uncommitted blocks we’ve staged via the previous steps or blocks that already exist in the file.
This means that if we want to write a block and put it in the middle of a file, we’d do the following:
- Stage the block with a unique id
- Ask the blob for all the current block ids
- Put our new block id at the appropriate place in the list of current block ids
- Commit the list of block ids with our new block id in it
Reading from block blobs
We can query an Azure Block blob for the list of blocks and how many bytes are in each.
The Azure Blob Storage API allows you to specify only a range of bytes to fetch. This means that using the list of blocks, we can figure out what byte range a given block exists in. Using these two mechanisms together, we’re able to fetch any given block from a file if we know the block id.
Our solution
The general structure we’ve created is as follows:
For each 10 minute interval, we create a new .avro file in our blob storage. The file names contain the time interval, e.g. 2020-01-01T13:30:00--2020-01-01T13:40:00 represents data between 13:30 and 13:40 on January 1st 2020.
The avro file consists of multiple rows. Each row corresponds to a sensor id, and contains the time-series data for the sensor in the given interval.
We split the avro file up into blocks as follows
- One block for the avro header. The
block idis something unique such as$$$_HEADER_$$$ - One block for each row in the avro file. The
block idhere is thesensor id.
 Each row in the avro file corresponds to a block in the Azure Block Blob.
They're even both called blocks!
Each row in the avro file corresponds to a block in the Azure Block Blob.
They're even both called blocks!
Querying For Specific Sensor Data
We allow querying for a time interval on a specific sensor id. First of, we have to calculate which files are relevant, when given an interval to search for. Depending on the interval you search for this could be multiple .avro files.
We do that by listing the file names in the blob storage. As each file name contains its interval, finding the right files is a matter of some reasonably simple string matching.
We can then use the unique properties of the block blobs and avro files to only fetch the data we need. As the sensor id is the block id of the block, we can quickly see which block contains the data for a particular sensor.
The process of extracting data for a specific sensor is then:
- Use the block list to figure out which block contains the avro row
- Fetch the header block and the block containing the sensor data
- Stitch the two blocks together to form a complete avro file.
- Parse the avro file and return the result
Writing and updating
The first time we’re writing data to an interval is pretty straightforward. We generate a header and stage that in the first block. Afterwards we stage each row of our avro files in a separate block. We then commit all the blocks we just staged.
Later on when we get new data for an interval, all we need to do is stage blocks with the new data. As mentioned previously when writing a row to an avro file, all we need is the schema and the sync marker.
So we can update our intervals like this:
- We fetch the header block from the existing file, and extract the schema and sync marker
- We stage each new row with the
sensor idas theblock id, using the schema and sync marker retrieved from above. - We commit the old block ids along with the newly staged ones. This allows us to update the old file with the new data,
without ever touching the old data.
In Summary
Our old system was based on the same principles of saving avro files to a blob storage, but didn’t use any of the fancy block functionality. This meant that when we had to query for a specific tag, we had to fetch the entire file, and then parse it on the client.
It also meant that when we wanted to append to a file, we had to download the old file, and merge it with the new data, taking much longer than it needs to.
Using some of the more advanced functions in the Azure blob storage allowed us to scale our API response time from 5s~ to less than 500ms, for large amounts of data while keeping the whole thing at a reasonable cost.
Did you enjoy this post? Please share it!
I'm Gustav (Mastodon), I'm currently a Staff Engineer at Climatiq, where we provide an API for all sorts of carbon emission accounting. I currently work mostly with Rust, but I've worked extensively with C#, Node, React, React Native, Typescript and Django.
All content on this website is written by a human. See the AI policy.
See an error? Submit a Pull Request and help fix it!
Back to the front page?